Python and Arabic NLP to Find Duplicate Topics and Articles

image source https://unsplash.com/photos/i_N0WH46YPM
Suppose you have a website containing thousands of articles and working with many content writers. In that case, the chances of having duplicate topics on your website are very high, especially if you keep changing your content plan from time to time.
In the Middle East and especially in the last five years, we had many new companies that focused on content production without focusing on the quality of the articles and topics. These sites are called content farms, where they publish articles on any topic. Each topic contains many articles trying to trick the search engines to get ranking on all the keywords.
The main goal of content farms (content mills) is to publish articles as much as possible to generate revenues from banners and sponsored content.
This model has been working and generating traffic and revenues for these companies in the last five years. Until Google's December 2020 update, all the Arabic content farms lost their ranking on Google SERPs. Even the big names in the Middle East lost ranking, and they started to shift to different content strategies and revenue models.
In this article, we will audit the content and find duplicate articles and topics using a Python script and NLP techniques to get the best results.
What Is the Difference Between Duplicate Articles and Keyword Cannibalization?
Keyword cannibalization is when more than one page is ranking on the same keyword. Keyword cannibalization is good if your position on Google SERPs is on the first three results.
Duplicate topics are a problem when you have more than one article discussing the same topic and have the same page title with minor differences.
Example of Duplicate Topics
- Article 1: 10 طرق للاقلاع عن التدخين
- Article 2: افضل الحلول للاقلاع عن التدخين
Another Example
- Article 1: ما هي فوائد الميرمية
- Article 2: فوائد الميرمية على الجسم
Every two articles talk about the same topic. By adding them on the same website, we confuse Google with which one to show on SERPs. And by the time, Google will ignore both of them and start to show results from other websites covering the same topic in one article.
Python and Arabic NLP
With Python and NLP, we will understand the Arabic text and classify them to determine which topics are duplicates. We will combine many Python libraries to get the results that we want.
in this tutorial, we will work on one of the top Arabic medical website content. I won't show the domain name and will replace it with example.com.
Getting the Data
First of all, we need to get the title of the articles. Some websites have the article's title in the URL. in our example today; the website has the full title in the URL, which will make our task very easy.
Some CMSs trim the title from the URL like WordPress, so don't rely on this method to get the titles.
Getting URLs From the XML Sitemap Using Python
We will start by getting the URLs from the XML sitemap using the below Python script.
Importing the libraries
import pandas as pd
from urllib.parse import unquote
import requests
from bs4 import BeautifulSoup as bs
Define the user agent and the XML sitemap that we want to get the URLs from
ua = "Mozilla/5.0 (Linux; {Android Version}; {Build Tag etc.}) AppleWebKit/{WebKit Rev} (KHTML, like Gecko) Chrome/{Chrome Rev} Mobile Safari/{WebKit Rev}"
website_url = "https://www.example.com/sitemap.xml"
Get the XML sitemap content and parse the URLs
posts_xml = requests.get(website_url ,headers={"User-Agent":ua})
posts_xml_content = bs(posts_xml.text,"xml")
posts_sitemap_urls = posts_xml_content.find_all("loc")Store the URLs in a Pandas data frame
xml_list = []
urls_titles = []
for item in posts_sitemap_urls:
xml_list.append(unquote(item.text))
xml_data = {"URL":xml_list}
xml_list_df = pd.DataFrame(xml_data,columns=["URL"])
xml_list_df.to_csv("example-urls.csv",index=False)
print("Done")Removing the Arabic Stopping Words
Stopping words are the words used in the Arabic language that add meaning to the sentence and are commonly repeated in the text. And if we remove them still, we can read the sentence and understand its meaning. That's why we will remove them in our script to get rid of the noise and get better results in the following steps.
Arabic Stopping Words
below are a sample of the Arabic stopping words that we will remove.
In the NLTK library, we have around 243 Arabic stopping words. I will list below the most used ones.

ألا,أم,أما,أن,أنا,أنت,أنتم,أنتما,أنتن,أنى,أو,أولئك,أولاء,إذن,إلا,إلى,إليك,إليكم,إليكما,إليكن,إما,إن,إنا,إنما,إنه,الذي,الذين,اللائي,اللاتي,اللتان,اللتيا,اللتين,اللذان,اللذين,اللواتيConvert the Words to Their Stem
Stemming reduces the word to its stem by removing letters at the beginning or end and sometimes in the middle. By stemming the words, we can compare them to each other to get the similarity.
Example of Stemmed Arabic Words
Origianl Text
البتراء أو البترا مدينة أثرية وتاريخية تقع في محافظة معان في جنوب المملكة الأردنية الهاشمية. تشتهر بعمارتها المنحوتة بالصخور ونظام قنوات جر المياه القديمة. أُطلق عليها قديمًا اسم "سلع"، كما سُميت بـ "المدينة الوردية" نسبةً لألوان صخورها الملتوية
Stemmed Text
بتراء او بترا مدين اثر تاريخ تقع في محافظ معان جنوب مملك اردن هاشم تشتهر عمار منحوت صخور نظام قنوا جر مياه قديم اطلق علي اسم سلع كما سمي ب ورد نسب لالو ملتو
Table View of Stemmed Text
| Original Word | Stemmed Word |
| البتراء | بتراء |
| مدينة | مدين |
| أثرية | اثر |
| محافظة | محافظ |
| المملكة | مملك |
| بعمارتها | عمار |
As you can see, there is no rule for stemming, but at least we can unify all the similar words to a new term that we can use later in our script.
Calculate Text Similarity
After removing the stopping words and converting the words to their stems, it is time to calculate the similarity between the article's titles. We can do this by using many Python libraries. We will use the Fuzzy Wuzzy library that works with the Arabic language.
And the last step is to add the data in a data frame to import them to an Excel sheet to start removing or merging the articles.
The Full Script With Explanations
Importing the libraries
import pandas as pd
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.isri import ISRIStemmer
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
from tqdm.notebook import tqdmReading the data from CSV file
data = pd.read_csv("source/example-data.csv")
data
As you can see, we have more than 40K pages. The next step is to filter only the articles pages by adding a new column with the page type. We can get the page type by reading the URL and extract its type from level 3.
data["Page Type"] = data["URL"].apply(lambda url : url.split("/")[3] )
dataNow we have a new column with the page type, and the next step is to create a new Dataframe for the articles pages.
articles_data = data.loc[data["Page Type"] == "articles"]Now we will remove the unnecessary characters from the URLs and keep only the title of the article.
def get_article_title(url):
try:
return url.split("/")[4].replace("-"," ").split("_")[0]
except:
return "No Title"
articles_data["Article Title"] = articles_data["URL"].apply(lambda url : get_article_title(url))And here is the final clean titles of the articles from the URLs
articles_data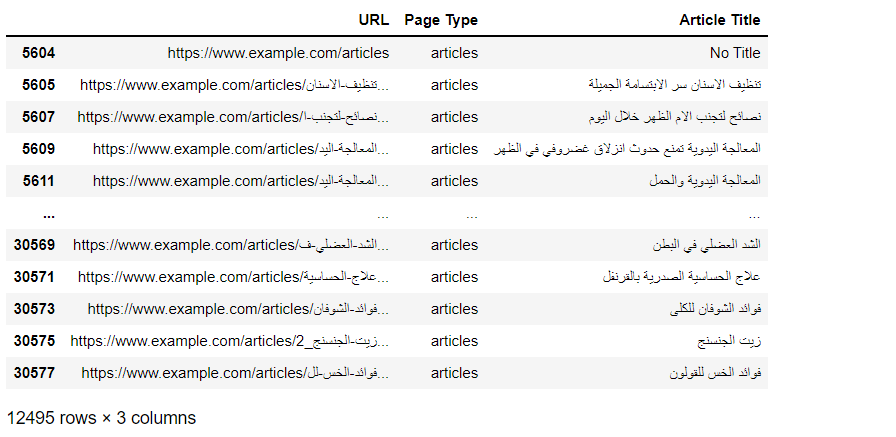
Now we will define a list of the Arabic stopping words and use ISRIStemmer for this task.
stop_words = set(stopwords.words('arabic'))
ps = ISRIStemmer()Then we will define a function to remove the stopping words and add them to a new column in our data frame
def clean_title(title):
clean_keyword = []
kw_levels = word_tokenize(title)
for kw_level in kw_levels:
if kw_level not in stop_words:
clean_keyword.append(ps.stem(kw_level))
return " ".join(clean_keyword)
articles_data["Clean Title"] = articles_data["Article Title"].apply(lambda title : clean_title(title))
articles_dataAnd here is how the data will look after removing the stopping words and stemming all the words.
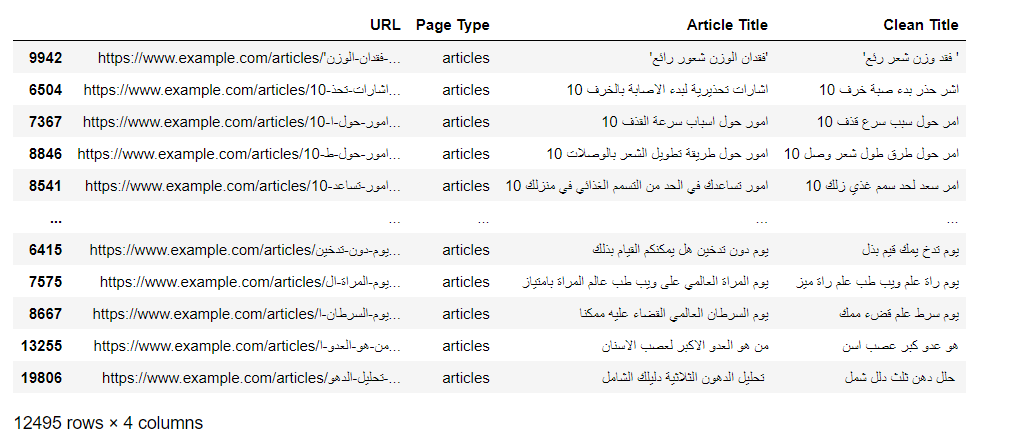
Sort the data by the clean title
articles_data = articles_data.sort_values(by="Clean Title", ascending=True)In our example, we have more than 12K articles. This will take too much time to process all the data. If you want to try on a small sample, you can get only the first 1000 or 3000 articles to try the script by adding the below line.
sample_articles_data = articles_data[:3000]We will go through all the titles one by one, compare the similarity with the complete list, and include in the final data frame only the titles with similarities of more than 90%.
origianl_title_1 = []
origianl_title_2 = []
origianl_url_1 = []
origianl_url_2 = []
score = []
for index,data_item in tqdm(sample_articles_data.iterrows()):
for index2,data_item2 in sample_articles_data.iterrows():
if data_item["Clean Title"] != data_item2["Clean Title"]:
score_item = fuzz.partial_ratio(data_item["Clean Title"],data_item2["Clean Title"])
if score_item > 90:
score.append(score_item)
origianl_title_1.append(data_item["Article Title"])
origianl_title_2.append(data_item2["Article Title"])
origianl_url_1.append(data_item["URL"])
origianl_url_2.append(data_item2["URL"])Define a dictionary and create the final data frame
articles_dic = {"Article 1":origianl_title_1,"Article 2":origianl_title_2,"Article 1 URL":origianl_url_1,"Article 2 URL":origianl_url_2,"Score":score}
articles_df = pd.DataFrame(articles_dic,columns=["Article 1","Article 2","Score","Article 1 URL","Article 2 URL"])Save the results in a CSV file.
articles_df.to_csv("results/results.csv",index=False)Results

This is a sample of the results, and we can see many articles talking about the same topic. Now you can start auditing the content and removing or merging the articles depending on the clicks and impressions of each one. You can get the performance data for each URL from the Google search console report or by using Python and Google Search Console API if you have more than 1000 URLs. I recommend using the script by Jean Christophe, it's very easy to implement, and I use it in all my scripts.
Related Posts




About the Author
