How to Get WordPress XML Sitemap URLs Using Python
You can get the URLs of any WordPress website by using Python libraries such as BeautifulSoup for scraping the XML sitemap content, Requests to make the requests, and the Pandas library to save the URLs in a data frame where you can export it later to Excel or Google sheets.
Image credit goes to https://unsplash.com/@strivingblogger
In this tutorial, you will learn how to get the URLs of any WordPress site that is using the Yoast SEO plugin
- What is the difference between XML sitemap and XML sitemap index
- How to get and read the content of the index XML sitemap file
- How to read all the posts XML sitemap
- Scraping the content of the XML
- Get the post title from the URL
- Saving the output in a CSV or XLS file
- Working with Arabic URLs and how to decode them in a UTF-8 format
What is The XML Sitemap Index
The XML sitemap index is a file that contains many XML sitemap files for your website, where you can use it to submit it to Google Search Console rather than submitting multiple files.
The best use of the XML sitemap index is for dynamic sites with many new pages every day that you need to include in the XML sitemap.
How Many URLs You Can Submit in a Single XML Sitemap File
You can submit up to 50,000 URLs in a single XML sitemap file, referring to Google's guidelines and rules on building XML sitemap files, plus their last updated date, images, and caption for the images.
Besides the 50K URLs, the size of your single XML sitemap file should be up to 50MB
Why Do You Need to Get the URLs From the XML Sitemap
There are many reasons to get the URLs from the XML sitemap for your site or any other website, such as:
Content Analysis for Your Competitors
When performing a competitor analysis, knowing how many pages they have is very important for building a content strategy and the frequency of publishing new content that you can use to compete with them.
Getting New Content Ideas
Think of it; having hundreds or thousands of URLs with titles and categories in an Excel sheet can help you develop or upgrade your content strategy.
Perform URL Indexing Audit for Your Website
Knowing how many published pages are on your website and comparing them to the number of indexed pages on Google is one of the first steps in the indexed pages audit.
You can know how many pages are indexed on your website by using the "Site:" operator on the Google search bar, example site:example.com
After comparing the number of published pages and the number of indexed pages on Google, your next step is to compare these numbers with the valid pages from Google Search Console and start analyzing what is happening to your URLs and which URLs to remove or fix.
You can contact me on my Linkedin profile if you have issues with your website URLs and want to set up a proper indexing strategy to optimize your SEO and reduce the hosting bills.
Libraries to Use to Get URLs From WordPress XML Sitemap
Requests
To make the requests on the XML site map index of the WordPress website.
BeautifulSoup
To parse and read the XML sitemap content.
Pandas
To save the output in a CSV or XLS format.
URLlib
To encode the Arabic URLs
Tqdm
To see the execution progress of your script.
Importing The Libraries
First, we'll start with importing the libraries in our Jupyter Notebook or any other Python IDE.
import pandas as pd
from urllib.parse import unquote
import requests
from bs4 import BeautifulSoup as bs
from tqdm.notebook import tqdm- If you don't have any of the listed libraries, you can install them using the pip command by writing pip install and the name of the library, example: pip install pandas.
- If you are using any IDE rather than notebooks, use import tqdm.
- You can ignore the URLlib library if you are not working with Arabic URLs. This library is very important for anyone working with Arabic SEO URLs
How to Get the Path of the XML Sitemap Index for Sites Using Yoast SEO Plugin
You can get the path of the XML sitemap index for Yoast SEO Plugin by typing /sitemap_index.xml after the domain name, for example:
https://www.example.com/sitemap_index.xml
Then a list of XML files will show up to you. In this tutorial, we'll focus on the posts files.
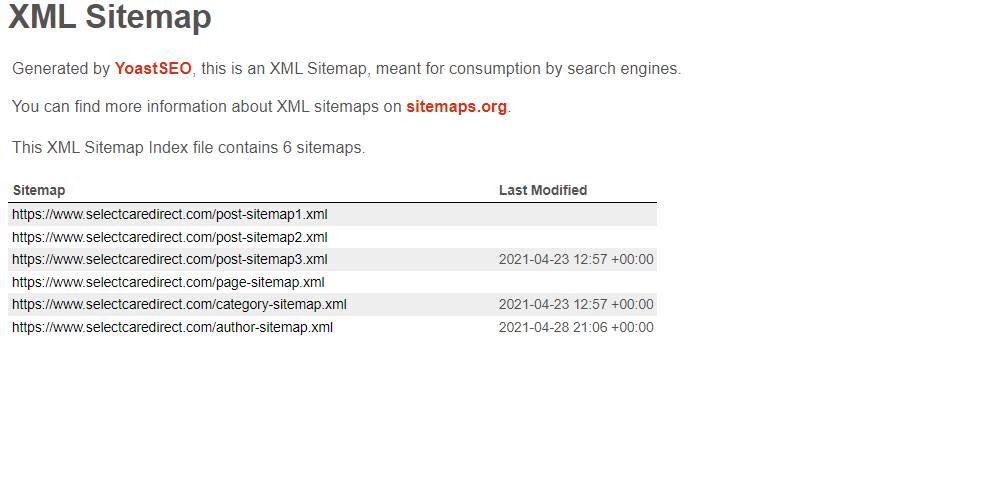
As you can see from the image, there are three posts files. The number of the files will help us in our loop.
The default naming for the posts files in the Yoast SEO plugin is post-sitemap{index}.xml, where the {index} is the number of the file.
Looping Over the Files and Perform the Requests
- Looping over the files and perform the requests
- To get the content of the XML files, we need to make HTTP requests on all the files. Here we will use a simple loop to read the files and get their content.
- Define an empty list to save the data
- Define a user agent to use in our requests
- Ignore the uploads files such as images and attachments
- Use unquote from urllib library to decode the Arabic URLs
- Get the title of the post by splitting the URL and get the last part of it.
- Prepare the Data Frame to store the data.
xml_list = []
urls_titles = []
for i in range(1,4):
xml = f"https://www.selectcaredirect.com/post-sitemap{i}.xml"
ua = "Mozilla/5.0 (Linux; {Android Version}; {Build Tag etc.}) AppleWebKit/{WebKit Rev} (KHTML, like Gecko) Chrome/{Chrome Rev} Mobile Safari/{WebKit Rev}"
xml_response = requests.get(xml,headers={"User-Agent":ua})
xml_content = bs(xml_response.text,"xml")
xml_loc = xml_content.find_all("loc")
for item in tqdm(xml_loc):
uploads = item.text.find("wp-content")
if uploads == -1:
xml_list.append(unquote(item.text))
urls_titles.append(unquote(item.text.split("/")[-2].replace("-"," ").title()))
xml_data = {"URL":xml_list,"Title":urls_titles}
xml_list_df = pd.DataFrame(xml_data,columns=["URL","Title"])
xml_list_df.to_csv("xml_files_results.csv",index=False)You can find the results in a file named xml_files_results.csv, where you can open it in Excel or Google sheets.
Related Posts




About the Author
